Evolution and its Adversaries (Part-3)

For readers to comprehend better, we are going back a few lines and illustrations. We may state at this point that, at the first read, some aspects might appear tough to grasp. But a second and third read will ease it up. After all, for some, it might be the first time they are exposed to information over which scores of scientists have won Nobel Prizes.
The 23 pairs of the DNA molecule
There are 46 chromosomes (23 pairs) in the nucleus of every one of the 70 trillion cells of a human body. But the sperm (of the male) and egg cells (of the female), have only 23 chromosomes. They combine to, once again, become 23 pairs (46 in all) at the time of fertilization. How these combine at the moment of fertilization, within virtually seconds, to produce a unique individual, is a fascinating story.

|
Critics of Darwinism Below is a short list – picked up randomly from science books – of biologists, naturalists, paleontologists, bio-chemists and others who have been critics, or have questioned, in whole or part, the evolutionary process as laid down by Darwin and the neo-Darwinists: Georges Cuvier, Richard Owen, Charles Lyell, H.G. Bronn, Wardlaw C.W., Ludwig Bertlanffy, D. Dewar, John Phillips, Stanley, S., Rensck, B., Beurlen, G.G. Simpson, Carter, G.S., Stuart Kauffman, John McDonald, George Miklos, Lin Margulis, Mae-Wan Ho, Peter Saunders, Michael Denton, Michael Behe, Stephen C. Meyer, William A Dembski, Walter A. Bradley, James Shapiro, Ohno S., Francisco Blanco and many others. |
Above: A pair of chromosomes: one out of the 23 pairs stored in the nucleus of every cell. The figure 23 sounds odd; but, remember that the Qur’an was revealed in 23 years. And the Prophet said, “I have been given the Qur’an, and something equivalent of it (i.e. the Sunnah).” So, the figure 23 shouldn’t sound so odd.
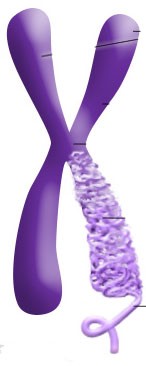
An enlarged pair of chromosomes, with one leg, showing how it is coiled to reduce storage size.
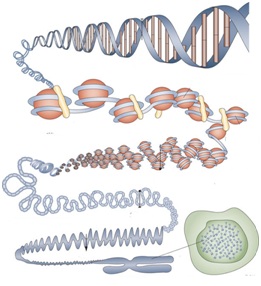
The illustration above shows one of the pairs of chromosomes, uncoiled, as it is taken out from the cell’s nucleus. The cell is shown at bottom-right, while the uppermost right corner shows the inner construction of the chromosome. Those (vertical) rods connecting the two arms of the ladder-like coiled strand are named ‘nucleotides.’
When the coil is unrolled, the chromosomes (or call them “DNA strands”) are themselves found to be twisted, like a ladder, or perhaps, like a rope, in which each strand (made of molecules) is a true copy of the other strand. So, we have not only the coded information of a whole body, on a single (chemical) strand, but a true copy of it on the other strand also, and the two are twisted together to become a rope. In other words, if you cut through the center of the chain (or the ladder), you will get two strands, each of which has the coded information in full for the entire human body.
Here is an illustration showing a small segment of the twisted ladder, in which the information is stored:
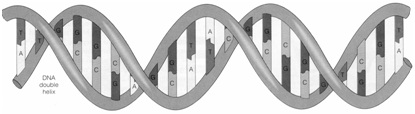
The figure above shows a segment of the chromosome. The step-like areas (the vertical rods) are made of smaller molecules (called nucleotides) joined together (in a chemical bond); and roughly, (not exactly), each twist as above carries information about one amino acid.
So, what are amino acids? Well, all proteins (there are some 100,000 kinds or types of them in a cell) are made from smaller molecules called amino acids. There are 20 different kinds of these amino acids. Unless various kinds of them are joined together, within the cell, say a 1000 of them, in a specific arrangement, the amino acids are, by themselves of no use. The source of these amino acids is the food we take. Our digestive system breaks food into several parts. Amino acids are one of the products. They are sent across from the intestine through blood circulation to the cells, throughout the body. They are allowed into the cell and are freely floating within it (the cytoplasm) until picked up by the ribosomes to be assembled into proteins. These proteins have a variety of functions within the cell.
To repeat: when amino acids are bonded together, in a very specific order (by a machiner called ribosome), they become a protein. There is no other way to make a protein. Of amino acids, there are 20 kinds, no more. The number of amino acid molecules that make up a protein varies from hundreds to thousands of units.

An Amino Acid
In the above, each ball represents an atom. The number of atoms in an amino acid is 15-20. There are 20 different kinds of amino acids. These amino acids, when linked together, in a specific way, (which only the cell can do), make proteins.
Proteins
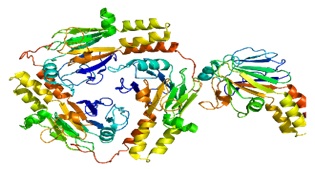
Illustration of a protein. All the little colored items you see are amino acids.
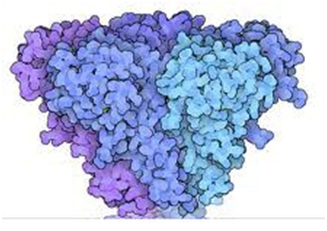
Another illustration of a protein
A protein consists of hundreds to thousands of amino acids. There are a 100,000 of different type of proteins in a human cell. Each of them has very specific shape and size, and only the cell can make it – with the help of ribosomes – from the free-floating amino acids inside the cell. Each of the protein performs a specific function. The information to manufacture the proteins comes from the DNA residing in the strong room called the nucleus. Sometime later, we might discuss this process of protein-making, Allah willing.
Who issues the command to make proteins? This is not known. It is not the DNA (or their sub-units called genes) which issue the command. The DNA only supplies the information, or details of the chemical combinations, that would make a specific protein.
The DNA
Back to the DNA; remember there are 23 pairs of them. They are in the form of a ladder (which is twisted), which, in turn, is made of tiny molecules (known as nucleotides), which carry information. Out of 23+23 DNA strings, each string contains the entire blueprint for the making of an organism (a biological body). So, the information is there on 23 strings, plus an entire copy of it.
There are some three billion pairs of nucleotide in each of the 23 pairs of the DNA. In their chemical arrangement, they are just the same in every one of the 70 trillion cells of a human body, because each cell is a true copy of the previous cell (biologists call the duplicated cell as the daughter cell). Thus, if we have a single cell, the information in the DNA alone is enough to build the entire body. This, however, is a text-book account. Research results obtained during last 20 years are saying something else. An account of this follows later. At the moment, we shall proceed with the above assumption, because most biology books, written even by serious scientists, are saying (incorrectly) that the entire information for building a body is in the DNA.
To recap: DNA is a large molecule. It is made from smaller molecules joined together in linear arrangement. Those smaller molecules are known as the nucleotides. There are four kinds of nucleotides. It is these which carry the information. Just like the English language being made of 26 letters, nucleotides are the four letters with which words are made. Those four letters are: A, C, T, and G. These four are the letters of the genetic language. Any three of them, let us say, ACT, or GTC, makes a word and carries, in code, the message for one of the 20 amino acids. Amino acids, you will remember, make a protein when joined together in a specific way. This happens inside the cell.
Thus, first, we have atoms. Then we have group of atoms in a particular order. They are called nucleotides. There are four kinds of these nucleotides, called A, C, T, and G. Three of these nucleotides placed together make the message for a specific amino acid. (There are 20 kinds of amino acids). These amino acids, when placed together in a specific order, make a specific protein, and all cellular machinery are called proteins.
So, from atoms to nucleotides to amino acids to proteins, to cells, to parts and limbs, to the body – that’s the whole story of every biological body.
Nucleotides
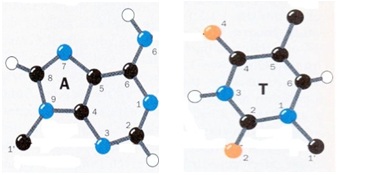
The above shows two of the nucleotides A and T.
The following chain in the DNA has 27 letters (nucleotides): TACTTCAGCTAGGATCTACCGGAACGT. It could be said that it has the information for nine amino acids, since every three of them codes for an amino acid. Let us assume the chain is 300 nucleotides long (since nine amino acids will make nothing). The 300 nucleotides would make 100 words. When these 100 words, each of which stands for a specific amino acid, are placed together, one linked to the other, then, it might be carrying in code the message for a certain protein. That is, assembled together, the 100 amino acids will result in a protein of a particular shape and size to perform a specific function within the cell. The sequence of the 100 amino acids, as coded by the DNA, must be strictly adhered to. If a single amino acid is misplaced in the chain which is 100 amino acids long, we will not get any protein, but merely a blob, good for nothing. The cell has a machinery (a specific protein) to destroy such blobs. This machinery is known as Lysosome. It degenerates all useless material floating around within the cell.
To Clarify
To explain a little: In how many different ways can 100 links of 20 amino acids can be joined together to get a protein? The answer is: in 10130 different sequences. In other words, 1 followed by 130 zeroes.
Now, keeping in mind that 20 amino acids, in a chain consisting of 100 links, can join up, hand-in-hand, in 10130 different ways, one can ask: How many of these 10130 different sequences are correct to produce a specific protein, useful in the cell (which will not be destroyed by Lysosome)? The answer is: “only one.” If you made a single mistake of misplacing one amino acid, anywhere in the chain you will not get the protein of your desire, but end up with a little molecular ball that is either useless to the body or even dangerous.
As an instance, the well-known sickle-cell disease (also known as Mongolism) is caused by the substitution of just one of the 146 amino acids in the protein known as hemoglobin. So, a single error can be fatal to the body. (Lifelines, p. 41)
What if we try to manufacture a protein in a laboratory, consisting of say 2000 links, which is common in human body? How many trials will have to be made before we hit at one – and only one – which will succeed in giving us a useful protein? Fred Hoyle and Chandra Wickramasinghe have worked it out as 102600 trials. (Our Place in the Cosmos, p. 151). In other words, out of a total of a figure 1 followed by 2600 zeroes, of different ways of joining together 20 amino acids of length 2000 links, only one will succeed if we tried our luck without knowing how to do it.
To some – not used to such figures as 10 followed by 2600 zeroes might not mean very much. It may be pointed out that the entire universe, including all galaxies and everything in it, is calculated to have 1080 atoms. That is, 10 followed by 80 zeroes. India’s mammoth population is 109 souls. So, 102600 is no mean figure.
But the cell assembles millions of amino acids, to make tens of thousands of proteins, every minute, all in one shot, without making a single error.
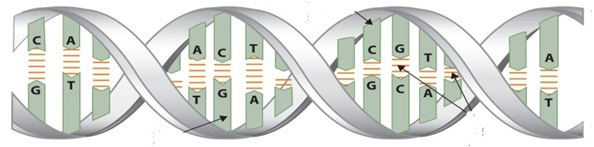
The above is a segment of the DNA. The whole – i.e., the complete strand – can be a meter long. Within it, as visible above, each of the three words “CGT” or “GCA” (see arrows) codes for an amino acid. The whole strand is nothing more than these ACT, TGA, CGT, GCA, etc. and no more.

Above: A segment of the coiled, ladder shaped DNA strand. It is also referred to as the ‘Double Helix’. The rods in between the two strands are nucleotides, one on each side. They are chemically, but weakly joined to each other, and can be easily separated. The whole can be a meter long. There are 23 of them in human cell. In the nucleus, where they are stored, they are in the double helix form.
At left of the illustration above, one strand is separated out. It is an exact copy of the other. Thus, there are 46 of these single strands; out of which every 23 contains all the data required to build a man.
The foregoing details should make it obvious the way Allah has concealed the information about a human being with regard to how his body works at the cellular level: first the body, then the organs, then the cell, then the nucleus, then the chromosome (DNA), then the genes (a segment of the DNA) – the last place where information is stored. This makes it hard for the humans, though not impossible, to tamper with themselves. What makes it further complicated is that genes alone do not always work independently.
But this is not all. Although the information coded with the help of ACT, CGT, etc. is on the DNA, stored with the help of three billion pieces of data, not all of it has meaning for the construction of a body. The truly useful information is further concealed in segments of the chromosome strands. These meaningful segments are called genes. There are some 21,000 of these genes, distributed over the 23 pairs of chromosomes, within every one of human cell. This (the gene) amounts to about 10% of the entire DNA. The rest has been, for long, considered junk (until the beginning of this century), though this is now proving untrue.
At all events, it can be said that, if we can read out 21,000 of these segments (genes) from the DNA strands, the whole body can be constructed, although of course, this is a theoretical statement. In actual fact, nothing of this sort can be achieved, because the data is useful within the cell. That is, the molecules (and so the message) that they code are useless outside the cell. Only the cell can read the information; not humans in, say, a laboratory. They can only read bits and pieces and learn by trial and error, sometimes as a result of thousands of experiments.
So, to make sure, genes are the useful data. The rest was called, and is still referred to by many scientists, as junk DNA. But research is now showing that the rest is not junk. This will become clear as we advance into details. For the moment, we shall move forward with the figure of 21,000 as the useful segments, i.e., the genes. Here is an illustration:
In the above, the chromosome strand, (the DNA), has been uncoiled. Although every rung of the ladder is coded for amino acids, it is only the pinked stretch that carries the message for a useful protein. The function of the rest [in blue] is not yet clear.
That is, when this stretch (in pink) is copied from the master chromosome (the copy known as mRNA), and sent out by the operators from within the nucleus, into the outer area (known as cytoplasm, within the cell), it is taken up by a machinery called ribosome. This machinery reads the message, (step by step, rung by rung, word by word), and learning in sequence what the mRNA (the gene) is coded for, picks up free-floating amino acids around it in the cytoplasm, assembles them in the order it reads the coded message, to finally produce the intended protein. Two thousand proteins are thus manufactured every second, by every cell in the body, round the clock, whether one is awake or sleeping. (Schroeder, https:// books. google.com.sa/books?id)
The above is a simple illustration. In actual fact, genes do not come in one long or short stretch, but rather, in the DNA strand as above; after the pink area, there may be useless stretch, and then again, another pink area, and then maybe a very long stretch of useless chain, and then again, another pink area; so that the three pink areas put together will make up for a gene, that codes for a single protein.
Now, every language needs comas, gaps, punctuation marks, full stops etc. to make a sortie of words meaningful. For example, if no spaces are given, the following means nothing:
ROMANCEMENTTOGETHERNOWHERE
With spaces introduced, it could read:
ROMAN CEMENT TOGETHER NOWHERE, where, at least all the four words are meaningful, though the whole does not yet make a meaningful statement. But if spaces are intelligently introduced, it could read:
ROMANCEMENT TO GET HER NOWHERE, which makes sense (though not to her).
(We regret we cannot recall where we took the unromantic example from, to assign the credit. At all events, it is not our making, but from a biology book).
In any case, how does the system know where to start reading in the chain of the DNA strand, and where to end? In the above illustration, the useless stretch is in pink and the useless stretch is in blue. But inside the cell, there are no colors. So, how do the operators recognize which areas to read and which not?
Well, care has been taken. A complete gene will usually have signs. To illustrate: the coded segment would have signs saying, “START READING HERE” and “STOP READING HERE.”
If amazement follows amazement, which will be followed by a greater amazement, and the best minds wonder and confess how it could have come to be at all, then we might remind ourselves of a simple statement from the Qur’an: “Allah has power over all things.”
(To be continued)
